
In questo articolo parleremo dei test per verificare se una variabile di interesse si distribuisce in modo normale o meno. Dopo una breve infarinatura su cosa sia la distribuzione normale andremo a vedere quali sono e come si interpretano i più importanti test per la verifica della normalità distributiva. Infine, vedremo come effettuare i test sui principali software statistici e cosa implica avere dei dati che si distribuiscono in modo normale o meno.
Cos’è la Distribuzione normale o Gaussiana
La distribuzione Normale (o distribuzione di Gauss) è una distribuzione di probabilità continua, spesso usata come prima approssimazione per descrivere variabili casuali a valori reali che tendono a concentrarsi attorno a un singolo valor medio. Il grafico della funzione di densità di probabilità associata è simmetrico e ha una forma a campana, nota come campana di Gauss. Le principali caratteristiche della curva della distribuzione normale sono le seguenti;
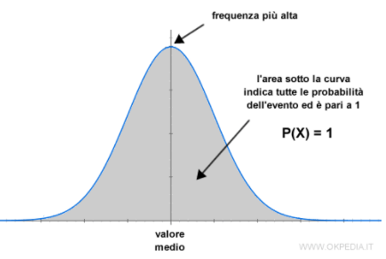
- La frequenza/probabilità più elevata coincide con il valore medio centrale e decresce spostandosi a destra o sinistra.
- L’area complessiva sotto la curva normale (grigia) è pari ad uno (ovvero 100%) poiché si tratta di una curva probabilistica e comprende i possibili eventi, ovvero tutti i possibili valori da più infinito a meno infinito. La superficie sotto la curva si può calcolare con un integrale.
- La curva Normale ha un valore pari a zero per quanto riguarda la Simmetria e tre per quanto riguarda la Curtosi (o pari a zero a seconda della tipologia di indice di curtosi scelto).
- Media moda e mediana coincidono con il valore centrale che ha anche la frequenza massima.
- Ogni curva normale viene univocamente identificata da due parametri: media e deviazione standard che ne determinano rispettivamente la posizione sull’asse delle X e “l’ampiezza” in termini di valori probabili
Per disegnare il grafico della distribuzione normale si utilizza un’apposita funzione f(x):

Un caso particolare della distribuzione normale è la distribuzione normale standardizzata con media uguale a zero e deviazione standard uguale a uno.
Capire come si distribuisce una variabile è molto importante quando si vuole generalizzare i risultati ottenuti da un campione di osservazione alla popolazione; questo passaggio in statistica è chiamato inferenza e si fa sfruttando le proprietà di alcune funzioni teoriche di riferimento.
Quando si lavora con campioni abbastanza numerosi l’andamento dei dati può essere modellato da una distribuzione di probabilità e quindi si possono utilizzare le tecniche statistiche parametriche.

Verifica della distribuzione normale: metodo grafico e test
Per verificare se i dati (che ricordiamo devono essere abbastanza numerosi e senza troppi outliers) si distribuiscono in modo normale i metodi sono due:
- Metodo grafico
- Test d’ipotesi
Il metodo grafico consiste nel rappresentare i nostri dati attraverso un istogramma e sovrapporgli la curva normale. Se la distribuzione teorica dei nostri dati è normale avremmo un istogramma che segue la curva con tutte (o comunque la maggior parte) delle “barre” al di sotto di questa; l’esempio riportato di seguito può essere considerato come caso ottimale.

I test per verificare la normalità distributiva dei dati sono diversi, quelli più comuni ed utilizzati sono:
- Shapiro-Wilk
- Kolmogorov-Smirnov
- Jarque-Bera
Per quanto riguarda il test Shapiro-Wilk l’ipotesi nulla (H0) è che la distribuzione teorica dei dati è normale mentre l’ipotesi alternativa (H1) è che la distribuzione teorica dei dati è un’altra. Se quindi il nostro p-value è maggiore della soglia di rifiuto alpha (da noi determinata, classicamente pari a 0,05), non rifiutiamo l’ipotesi nulla di dati provenienti da una distribuzione normale, se invece il p-value viene “piccolo”, ovvero inferiore ad alpha scelto, andremo a rifiutare l’ipotesi nulla di normalità distributiva concludendo che la nostra variabile ha una distribuzione significativamente diversa dalla distribuzione di Gauss.
Per quanto riguarda il test Kolmogorov-Smirnov esistono due versioni:
La prima ha come ipotesi nulla (H0) che la distribuzione teorica dei dati è normale mentre l’ipotesi alternativa (H1) è che la distribuzione teorica dei dati è un’altra. Se quindi il nostro p-value è maggiore della soglia di rifiuto alpha, non rifiutiamo l’ipotesi nulla di dati provenienti da una distribuzione normale.
La seconda (conosciuta anche come test Kolmogorov-Smirnov per campioni indipendenti) prende in input due variabili e ha come ipotesi nulla (H0) che la distribuzione teorica delle due variabili è la stessa mentre l’ipotesi alternativa (H1) è che la distribuzione teorica è diversa.
Il test di Jarque-Bera è invece indicato per dati di tipo serie storiche in quanto basato sul valore dell’asimmetria e della curtosi; si tratta di un test di normalità che verifica simultaneamente se la simmetria e la curtosi sono coerenti con i valori che dovrebbero assumere sotto l’ipotesi nulla di normalità, ossia rispettivamente 0 e 3. Sotto l’ipotesi nulla (H0) la distribuzione dei dati è una Chi-quadro con 2 gradi di libertà.
Come fare un test di Normalità in SPSS, R, STATA ed EXCEL
Andiamo ora a vedere come effettuare i test per la verifica della normalità distributiva con i principali software statistici. Ci focalizzeremo principalmente sui programmi STATA, SPSS e R; su Excel invece il discorso è più complesso in quanto non esistono funzioni in grado di effettuare rapidamente i test per la normalità. Nello specifico, bisognerebbe calcolare a mano le diverse statistiche test e le varie frequenze (a seconda del test), per poi ricavare il p-value utile per il rifiuto o meno dell’ipotesi nulla. Vista la complessità dei calcoli non consigliamo l’utilizzo di Excel per lo svolgimento dei test di normalità.
Stata è il software con cui effettuare nel modo più rapido i tre test sopra illustrati in quanto le funzioni sono già installate e non richiedono l’utilizzo di pacchetti diversi da quello base. Il test di Shapiro-Wilk si effettua con il comando “swilk” seguito dal nome della variabile; allo stesso modo il test di Kolmogorov-Smirnov (comando “ksmirnov” per entrambe le versioni) e il test di Jarque-Bera (comando “sktest”).
Su R invece il test di Shapiro-Wilk si effettua con il comando shapiro.test(“nome variabile”); la prima versione del test di Kolmogorov-Smirnov con il comando ks.test(“nome variabile”,”pnorm”), mentre la seconda versione con il comando ks.test(“nome prima variabile”,”nome seconda variabile”). Per quanto riguarda il test di Jarque-Bera invece abbiamo bisogno di scaricare e installare il pacchetto “tseries” e il comando è jarque.bera.test(“nome variabile”).
Infine, su SPSS, dei tre test illustrati sono due sono facili da mettere in pratica, ovvero il Shapiro-Wilk e il Kolmogorv-Smirnov, mentre il Jarque-Bera richiede alcuni passaggi in più che non saranno discussi in questo momento. Per eseguire il test di Shapiro-Wilk bisogna andare su Analizza -> Statistiche descrittive -> Esplora e, dopo aver inserito i dati di cui vogliamo verificare la normalità, bisogna cliccare sul tasto “Grafici”. Nella finestra che si aprirà andremo a “flaggare” la scritta “Grafico di Normalità con test” che ci darà in output il test di Shapiro-Wilk. Il test di Kolmogorov-Smirnov (prima versione) invece si esegue cliccando su Analizza -> Test non parametrici -> Finestra di dialogo legacy -> K-S per 1 campione. Nella finestra che si aprirà dovremmo “flaggare” la scritta “Normale” come distribuzione del test. Per effettuare la seconda versione del test il percorso è lo stesso tranne per l’ultima parte in cui dovremmo cliccare su “2 Campioni indipendenti”.


Violazione della normalità : Regressione e Test Non Parametrici
Verificare se i dati si distribuiscono in modo normale o meno risulta essere fondamentale per diverse analisi che si effettuano durante lo studio dei dati. In primis, per poter effettuare un modello di regressione lineare, la variabile dipendente deve distribuirsi in modo Normale, altrimenti il modello potrebbe non essere considerato valido.
Inoltre, come già accennato in precedenza, se i nostri dati si distribuiscono in modo normale possiamo utilizzare i più classici test parametrici come i t-test o il test Anova; al contrario, se la distribuzione della variabile di interesse non è normale siamo costretti ad utilizzare test non parametrici come Wilcoxon, Mann-Whitney o Kruskal-Wallis.
Ovviamente è molto difficile che una variabile si distribuisca perfettamente in modo normale, quindi molte volte, anche se i test danno esito negativo, si può essere tolleranti e accontentarsi di rispettare determinate condizioni, ovvero:
- Numerosità accettabile;
- Assenza di outliers;
- Valore medio approssimativamente uguale al valore mediano;
- Valore della simmetria e della curtosi approssimativamente uguali a 0 e 3.

Se hai dubbi sui test di normalità o se vuoi una consulenza statistica per essere supportato nell’analisi statistica dei tuoi dati puoi sempre scriverci per avere un preventivo o per prenotare una consulenza senza impegno!
Articolo a cura del Dott. Iacopo Moses



